Some time ago now I was lucky enough to take part in Ruxcon CTF, which was absolutely awesome - learnt bunch of new things and met heaps of cool people!
There was a wide variety of different challenges, but this particular one REALLY did my head in. I spent way too much time on it during the CTF and unfortunately didn’t manage to break it. Then recently, I decided to take a look at it again and, with a lot less hassle than I thought, I nailed it!
Let me introduce you to my most hated PNG of all times…
Introduction
Alright, let’s get started, the goal is to find the flag in the following packet capture.
Before we get to it, I owe a huge shout-out to TheColonial for directing me onto the right path when solving this one… simply, sometimes it’s best to write your own tools!
Diving into packet capture
Looking at the packet capture, we can quickly see that it’s an SMTP traffic. Let’s have a closer look at the TCP stream (right click on any packet of interest -> Follow TCP Stream).
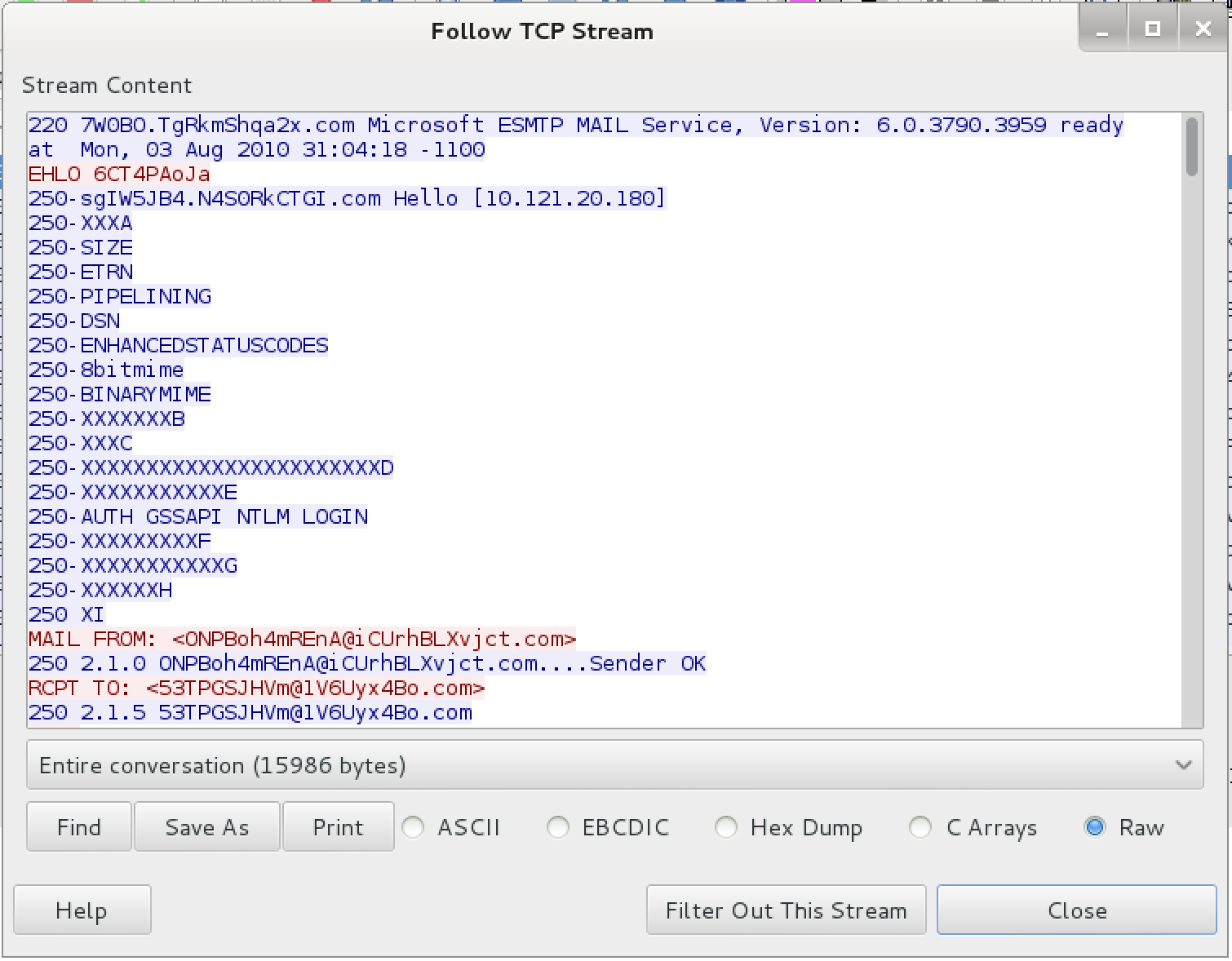
Looks like the transmitted email message will be of the most interest to us - let’s extract it:
- Select to show packets going one way only (to the server)
- Save as raw data extract
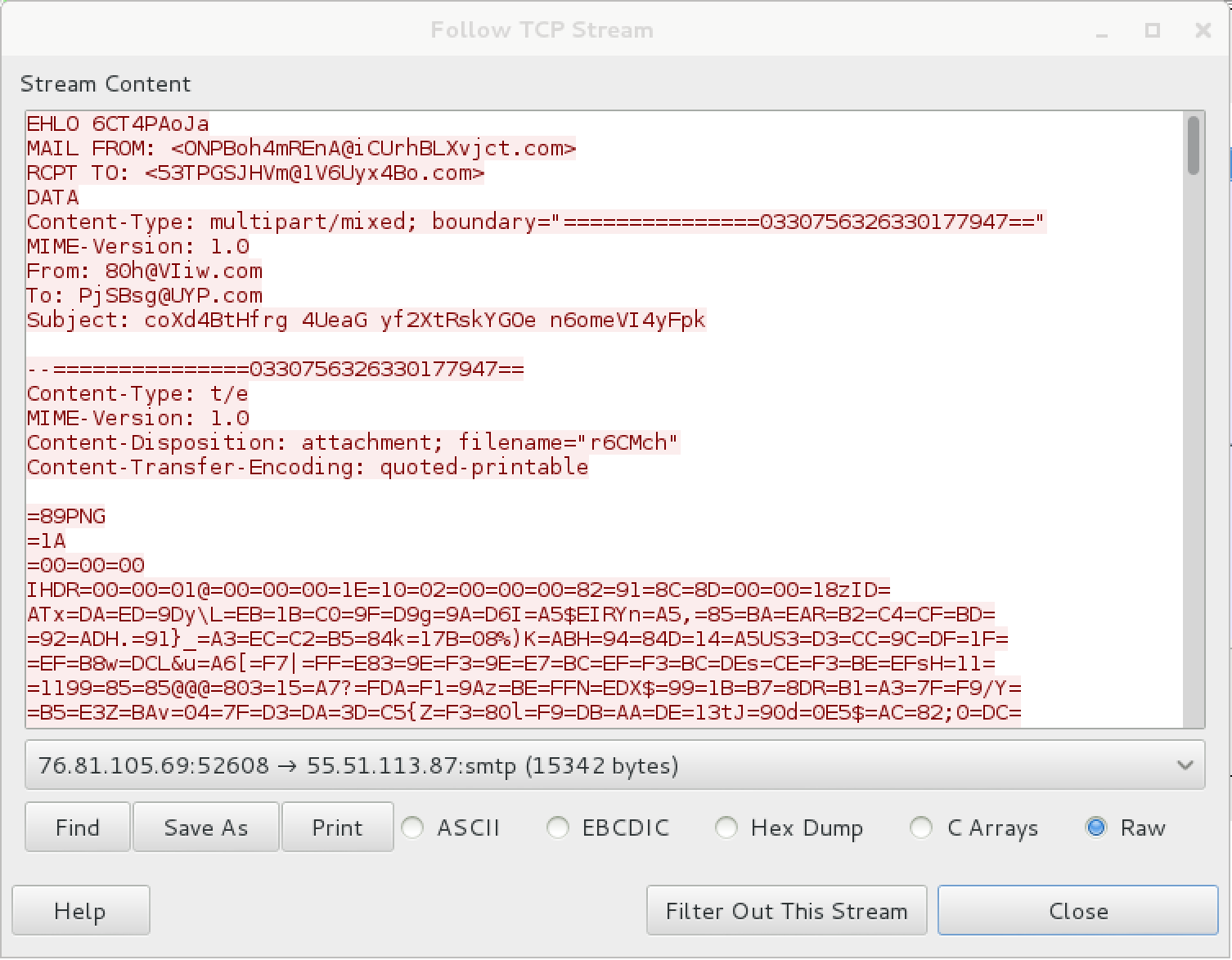
Raw email
Ok, so we have extracted email from the packet capture. Looking at the email, we can see that there’s not much of useful plaintext information in the email (subject is just some gibberish), but there’s an attachment that we’ll need to focus on.
Few things on the attachment looking at the MIME headers and the attachment itself:
- it’s encoded as quoted-printable
- it looks like a PNG file (looking at first few bytes of the attachment)
Let’s remove all email relevant lines from the file and leave only quoted-printable PNG, making it look like this:
1 2 3 4 5 6 7 8 9 10 11 | |
Cool, so we have a quoted-printable PNG file. There’s a problem though - there are carriage returns added before every meaningful new line (part of quoted-printable encoding)! They’re easily visible when you open it up, for example, in vim.
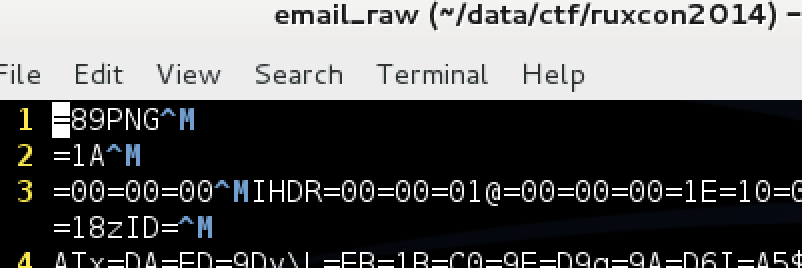
Right… let’s keep that in mind, it’s something we’ll need to get rid of.
Plan of attack
There are couple things we already know about the attachment, so we can have some sort of a plan of attack. Seems that we’ll need to do the following:
- decode quoted-printable file
- get rid of CRs before new lines
- ensure we haven’t corrupted PNG file header
Seems pretty straight forward!
And that’s exactly what I was also trying to do during the CTF, however, I was using pre-made tools for everything! I found some website that was accepting quoted printable files and spitting out decoded version, then I was using vim with xxd to get rid of CRs and manually playing with PNG file header.
It was all resulting in a corrupted PNG throwing all kinds of different errors. After lots of research, frustration and talking to OJ, I have decided to write my own tool to do it all for me.
Quoted-Printable
Before we start, few words on Quoted-Printable encoding. There are couple of rules that we’ll need to keep in mind:
- any 8 bit value may be encoded with 3 characters:
=, followed by two hex digits representing the byte’s numberic value - all printable ASCII characters are represented as themselves (no
=required) - all lines cannot be longer than 76 characters, soft line breaks may be added (
=at the end of the line) to allow encoding very long lines without line breaks
PNG header
Also, it’s important to understand how PNG header looks like and why.
{kind=link}
1 2 | |
- First two bytes distinguish PNG files on systems that expect the first two bytes to identify the file type. It also catches bad file transfers that clear bit 7.
- The next 3 bytes represent name of the format
- The CR-LF sequence (
0d 0a) catches bad file transfers that alter new line sequences 1astops file display under MS-DOS- The final LF checks for the inverse of the CR-LF translation problem
Writing own decoder
Okay, so now we have a good understanding of the theory behind it all, so let’s code something up!
Again, recapping, what we’ll need to do is:
- decode quoted printable, following basic rules listed above and ensuring to handle soft line breaks properly (i.e. omit decoding of them)
- get rid of CRs from CR-LF sequences, except the one from the PNG header
The following Python code does it all.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
Run it on the previously extracted raw email file.
1
| |
And open up output.png file.
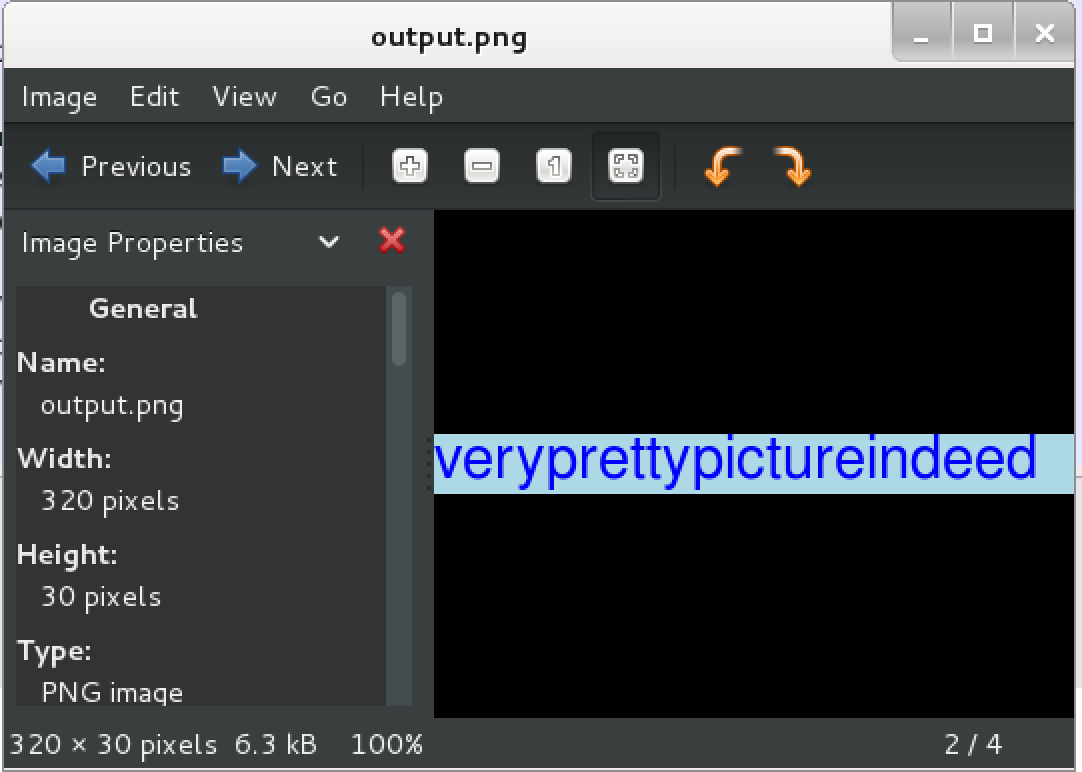
That’s it!
Summary
It was actually a lot easier than I thought… once you know the theory behind it all, understand what’s the actual problem we’re facing here (CR-LF conversion issue) and write your own tool to do it (not sure why all of the tools I tried didn’t do it properly), it’s actually not that hard… and only handful of people managed to complete it at the CTF!
Looking back at it, it was pretty frustrating, but I didn’t take time to properly read through all the basics during the CTF and I was trying to quickly hack some ad-hoc solution, which didn’t work well at all. I guess the time pressure and the thought that “there are so many other challenges to hack to get points” sometimes takes over calm, logical thinking. Next time I’ll try to take a step back and really ask myself “what are we trying to solve here”.
I’m so glad I managed to finish it, it was really doing my head in and, in the end, I learnt a lot from it!